

Large Language Models (LLMs) show superior performances even compared with expert physicians. However, how to effectively harness the new capabilities in the real clinical setting is underexplored. Probing into the reasoning process and verifying the clinical decision-making procedure is crucial for integration into the hospital setting. With the purpose of "debugging" medical LLMs, I propose a novel interface **LLMXAI** that uses sparse autoencoders (SAE) to identify interpretable features and compare with the real explanation given by domain experts.
引言
大型语言模型(LLM)在医学问答(Medical Question Answering)任务中表现出色,其性能已达到普通医务人员甚至部分专家医生的水平。代表性模型包括 Medi-Gemini (Saab et al., 2024) 和 Med-Palm2 (Singhal et al., 2023) 。
近年来,学术界 (Kim et al., 2025) 与产业界持续开展针对韩语医疗数据的 LLM 评测与适配研究。截至 2025 年 12 月 1 日,当前产业界模型在相关基准测试中的表现如表 1 所示:
| 模型 / Agent | 开发机构 | 平均得分 |
|---|---|---|
| KMed | SNUH-NAVER | 96.40 |
| GPT-5.1 | OpenAI | 95.99 |
| GPT-5 | OpenAI | 93.62 |
| Claude Sonnet 4.5 | Anthropic | 94.86 |
| Qwen 235B Think | Alibaba Cloud | 90.14 |
| DeepSeek R1-0528 | DeepSeek | 89.66 |
| Solar Pro 2 | Upstage | 88.55 |
| A.X-4.0 | SK Telecom | 85.60 |
| LLAMA-4 Maverick | Meta | 85.59 |
| Qwen3 32B | Alibaba Cloud | 82.24 |
| EXAONE-4-32B | LG AI Research | 84.14 |
| Open Evidence | Open Evidence | 69.11 |
表:产业界 LLM 在韩国医师执照考试(KMLE)2025 上的成绩。
依赖 LLM 生成解释时,一个重要问题是 推理保真度(reasoning fidelity)。模型往往会事后生成看似合理的解释(post-hoc justification),而真实推理过程与事后合理化之间的界限仍难以区分。
在本研究中,我们从 LLM 的内部激活(activations)中提取可解释特征(interpretable features),并分析这些特征与专家提供的医学解释之间的对应关系。
用于特征提取的 Sparse Autoencoder
Sparse Autoencoder(SAE)通过学习过完备(overcomplete)的特征字典来缓解神经网络中的多义性(polysemanticity)问题。它能够将激活向量表示为稀疏线性组合,其中每个特征方向理想情况下对应一个单独且可解释的概念 (Cunningham et al., 2023) 。
给定语言模型某一层的激活向量集合
\[\{\mathbf{x}_i\}_{i=1}^{n} \subset \mathbb{R}^{d_{\text{in}}}\]SAE 学习一个特征字典
\[\{\mathbf{f}_k\}_{k=1}^{d_{\text{hid}}} \subset \mathbb{R}^{d_{\text{in}}}\]其中
\[d_{\text{hid}} = R \cdot d_{\text{in}}, \quad R > 1\]为扩展系数(expansion factor)。
该自编码器由编码器和解码器组成:
\[\begin{aligned} \mathbf{c} &= \text{ReLU}(\mathbf{W}_{\text{enc}}\mathbf{x} + \mathbf{b})\\ \hat{\mathbf{x}} &= \mathbf{W}_{\text{dec}}\mathbf{c} = \sum_{k=1}^{d_{\text{hid}}} c_k \mathbf{f}_k \end{aligned}\]其中
\[\mathbf{W}_{\text{enc}} \in \mathbb{R}^{d_{\text{hid}} \times d_{\text{in}}}, \quad \mathbf{b} \in \mathbb{R}^{d_{\text{hid}}}\]并采用权重共享(tied weights):
\[\mathbf{W}_{\text{dec}} = \mathbf{W}_{\text{enc}}^T\]解码器中的列向量 \(\mathbf{f}_k\) 构成学习得到的特征字典,并经过 \(\ell_2\) 归一化。
训练目标为最小化以下损失函数:
\[\mathcal{L}(\mathbf{x}) = \underbrace{\|\mathbf{x}-\hat{\mathbf{x}}\|_2^2}_{\text{重建误差}} + \underbrace{\alpha \|\mathbf{c}\|_1}_{\text{稀疏性约束}}\]其中 \(\alpha > 0\) 控制重建精度与稀疏性之间的权衡。
\(\ell_1\) 正则项鼓励稀疏激活,从而帮助发现单义特征(monosemantic features),使每个特征对应单一可解释概念 (Olshausen & Field, 1997) 。研究表明,这些特征比单个神经元或 PCA、ICA 等线性分解方法更具可解释性 (Cunningham et al., 2023) 。
医学问答数据集与模型
KorMedMCQA (Kweon et al., 2024) 是基于韩国医疗专业资格考试构建的多项选择问答基准数据集,其中包含 2,494 道医生资格考试题目。
本研究重点分析开源医疗 LLM 中的可解释特征。实验模型包括 Hari-q3 (SNUH, 2025) —— 据报道,该模型在 KorMedMCQA 医师考试推理题上的准确率达到 84.14% —— 以及其他通用开源模型。
LLMXAI:医学问答数据解释界面
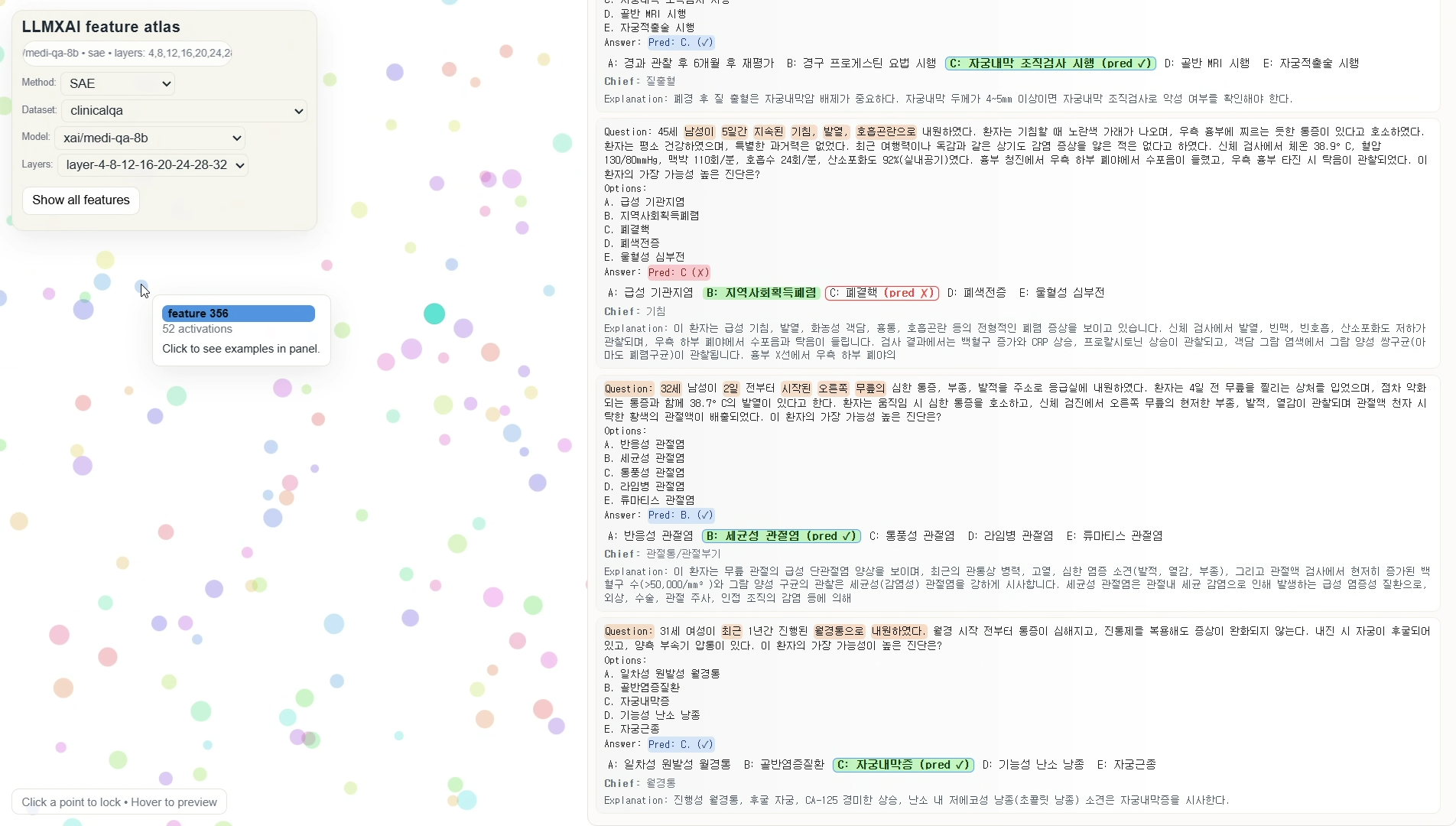
该界面在右侧面板展示提取出的特征及其相关文本语料。界面同时显示问题与选项、模型预测结果与正确答案,以及专家提供的解释说明。
未来方向
目前我正在实现上述界面,并在不同数据集与模型上开展实验。
此外,我计划利用医学领域知识分析 LLM 内部激活模式,并将其与专家提供的解释进行对比评估。同时,也可以通过增强或抑制特定特征来实现对 LLM 的行为引导(steering)。
作为扩展研究,我还将探索 Sparse Feature Circuits (Marks et al., 2025) 、Automated Circuit Discovery (Bhaskar et al., 2024) 以及其他 Transformer Circuit 相关方法 (Elhage et al., 2021); (Dunefsky et al., 2024)。
未来工作将重点研究如何构建更符合临床推理过程的人机交互方式,使医疗 LLM 在可操控性(steerability)、可验证性(verifiability)以及可解释性(explainability)方面得到进一步提升。
References
- Saab, K., Tu, T., Weng, W.-H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother, T., Park, C., Vedadi, E., & others. (2024). Capabilities of Gemini Models in Medicine. ArXiv Preprint ArXiv:2404.18416.
- Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., & others. (2023). Towards Expert-Level Medical Question Answering with Large Language Models. ArXiv Preprint ArXiv:2305.09617.
- Kim, H. J., Jung, K., Shin, S., Lee, W., Lee, J. H., Park, H. S., & Choi, Q. (2025). Performance evaluation of large language models on Korean medical licensing examination: a three-year comparative analysis. Scientific Reports, 15(1), 36082. doi: 10.1038/s41598-025-20066-x
- Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models. ArXiv Preprint ArXiv:2309.08600.
- Olshausen, B. A., & Field, D. J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by V1? Vision Research, 37(23), 3311–3325.
- Kweon, S., Choi, B., Chu, G., Song, J., Hyeon, D., Gan, S., Kim, J., Kim, M., Park, R. W., & Choi, E. (2024). KorMedMCQA: Multi-Choice Question Answering Benchmark for Korean Healthcare Professional Licensing Examinations. ArXiv Preprint ArXiv:2403.01469.
- SNUH, H. A. I. R. I. (H. A. R. I.- S. N. U. H. (2025). Hari-q3. https://huggingface.co/snuh/hari-q3
- Marks, S., Rager, C., Michaud, E. J., Belinkov, Y., Bau, D., & Mueller, A. (2025). Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models. The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=I4e82CIDxv
- Bhaskar, A., Wettig, A., Friedman, D., & Chen, D. (2024). Finding Transformer Circuits With Edge Pruning. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=8oSY3rA9jY
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., & others. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. https://transformer-circuits.pub/2021/framework/index.html
- Dunefsky, J., Chlenski, P., & Nanda, N. (2024). Transcoders find interpretable LLM feature circuits. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=J6zHcScAo0