

Large Language Models (LLMs) show superior performances even compared with expert physicians. However, how to effectively harness the new capabilities in the real clinical setting is underexplored. Probing into the reasoning process and verifying the clinical decision-making procedure is crucial for integration into the hospital setting. With the purpose of "debugging" medical LLMs, I propose a novel interface **LLMXAI** that uses sparse autoencoders (SAE) to identify interpretable features and compare with the real explanation given by domain experts.
서론
대규모 언어 모델(LLM)은 의료 질의응답(Medical Question Answering) 과제에서 효과적인 성능을 보이고 있으며, 평균적인 의료진 수준 또는 경우에 따라 전문의 수준에 필적하는 결과를 달성하고 있다. 대표적인 예로는 Medi-Gemini (Saab et al., 2024) 와 Med-Palm2 (Singhal et al., 2023) 가 있다. 최근에는 한국어 의료 데이터에 LLM을 평가하고 적응시키기 위한 연구가 학계 (Kim et al., 2025) 와 산업계에서 활발히 진행되고 있다. 현재 산업계 모델들의 최신 벤치마크 결과는 표 1에 제시되어 있다 (2025년 12월 1일 기준).
| 모델 / 에이전트 | 개발사 | 평균 점수 |
|---|---|---|
| KMed | SNUH-NAVER | 96.40 |
| GPT-5.1 | OpenAI | 95.99 |
| GPT-5 | OpenAI | 93.62 |
| Claude Sonnet 4.5 | Anthropic | 94.86 |
| Qwen 235B Think | Alibaba Cloud | 90.14 |
| DeepSeek R1-0528 | DeepSeek | 89.66 |
| Solar Pro 2 | Upstage | 88.55 |
| A.X-4.0 | SK Telecom | 85.60 |
| LLAMA-4 Maverick | Meta | 85.59 |
| Qwen3 32B | Alibaba Cloud | 82.24 |
| EXAONE-4-32B | LG AI Research | 84.14 |
| Open Evidence | Open Evidence | 69.11 |
표: 한국 의사 국가시험(KMLE) 2025에 대한 산업계 LLM 성능 결과.
LLM이 생성한 설명에 의존할 때의 주요 문제 중 하나는 추론 충실도(reasoning fidelity) 이다. 모델은 종종 그럴듯한 설명을 사후적으로 만들어내며(post-hoc justification), 실제 추론 과정과 사후 설명을 구분하는 것은 여전히 어려운 문제로 남아 있다. 본 연구에서는 LLM 내부 활성화(activations)로부터 해석 가능한 특징(interpretable features)을 추출하고, 이들이 전문가가 제공한 설명과 어떻게 대응되는지 분석한다.
특징 추출을 위한 Sparse Autoencoder
Sparse Autoencoder(SAE)는 과완비(overcomplete) 특징 사전(feature dictionary)을 학습함으로써 신경망의 다의성(polysemanticity) 문제를 해결한다. 이를 통해 활성화 벡터를 희소한 선형 결합으로 재구성할 수 있으며, 각 특징 방향(feature direction)은 이상적으로 하나의 해석 가능한 개념을 나타낸다 (Cunningham et al., 2023) .
언어 모델의 특정 계층으로부터 얻어진 활성화 벡터 집합 \(\{\mathbf{x}_i\}_{i=1}^{n} \subset \mathbb{R}^{d_{\text{in}}}\) 가 주어졌다고 하자. SAE는 다음과 같은 특징 사전을 학습한다.
\[\{\mathbf{f}_k\}_{k=1}^{d_{\text{hid}}} \subset \mathbb{R}^{d_{\text{in}}}\]여기서
\[d_{\text{hid}} = R \cdot d_{\text{in}}, \quad R > 1\]은 확장 계수(expansion factor)이다.
오토인코더는 활성화를 희소 특징 계수 \(\mathbf{c} \in \mathbb{R}^{d_{\text{hid}}}\) 로 변환하는 인코더와, 원래 활성화를 복원하는 디코더로 구성된다.
\[\begin{aligned} \mathbf{c} &= \text{ReLU}(\mathbf{W}_{\text{enc}}\mathbf{x} + \mathbf{b})\\ \hat{\mathbf{x}} &= \mathbf{W}_{\text{dec}}\mathbf{c} = \sum_{k=1}^{d_{\text{hid}}} c_k \mathbf{f}_k \end{aligned}\]여기서
\[\mathbf{W}_{\text{enc}} \in \mathbb{R}^{d_{\text{hid}} \times d_{\text{in}}}, \quad \mathbf{b} \in \mathbb{R}^{d_{\text{hid}}}\]이며, 가중치 공유(tied weights)를 사용하여
\[\mathbf{W}_{\text{dec}} = \mathbf{W}_{\text{enc}}^T\]로 설정한다.
디코더의 열 벡터 \(\mathbf{f}_k\) 는 학습된 특징 사전을 구성하며, \(\ell_2\) 정규화가 적용된다.
학습은 다음 손실 함수를 최소화하는 방식으로 수행된다.
\[\mathcal{L}(\mathbf{x}) = \underbrace{\|\mathbf{x}-\hat{\mathbf{x}}\|_2^2}_{\text{재구성 손실}} + \underbrace{\alpha \|\mathbf{c}\|_1}_{\text{희소성 패널티}}\]여기서 \(\alpha > 0\) 는 희소성과 재구성 정확도 사이의 균형을 조절하는 하이퍼파라미터이다.
\(\ell_1\) 패널티는 희소 활성화를 유도하며, 각 특징이 하나의 해석 가능한 개념을 나타내는 단의미적(monosemantic) 특징을 발견할 수 있도록 한다 (Olshausen & Field, 1997) . 이러한 접근법은 개별 뉴런이나 PCA, ICA와 같은 선형 분해 방법보다 훨씬 더 해석 가능한 특징을 제공하는 것으로 알려져 있다 (Cunningham et al., 2023) .
의료 질의응답 데이터셋 및 모델
KorMedMCQA (Kweon et al., 2024) 는 한국 의료인 국가시험을 기반으로 구축된 객관식 질의응답 벤치마크로, 의사 국가시험에 해당하는 2,494개의 문제를 포함하고 있다.
본 연구에서는 공개 의료 LLM에서 추출한 해석 가능한 특징을 분석한다. 사용 모델에는 Hari-q3 (SNUH, 2025) 가 포함된다. 이 모델은 KorMedMCQA 데이터셋의 의사 시험 추론 문제에서 84.14%의 정확도를 보이는 것으로 보고되었으며, 그 외 여러 범용 공개 모델들도 함께 사용된다.
LLMXAI: 의료 질의응답 데이터 분석 인터페이스
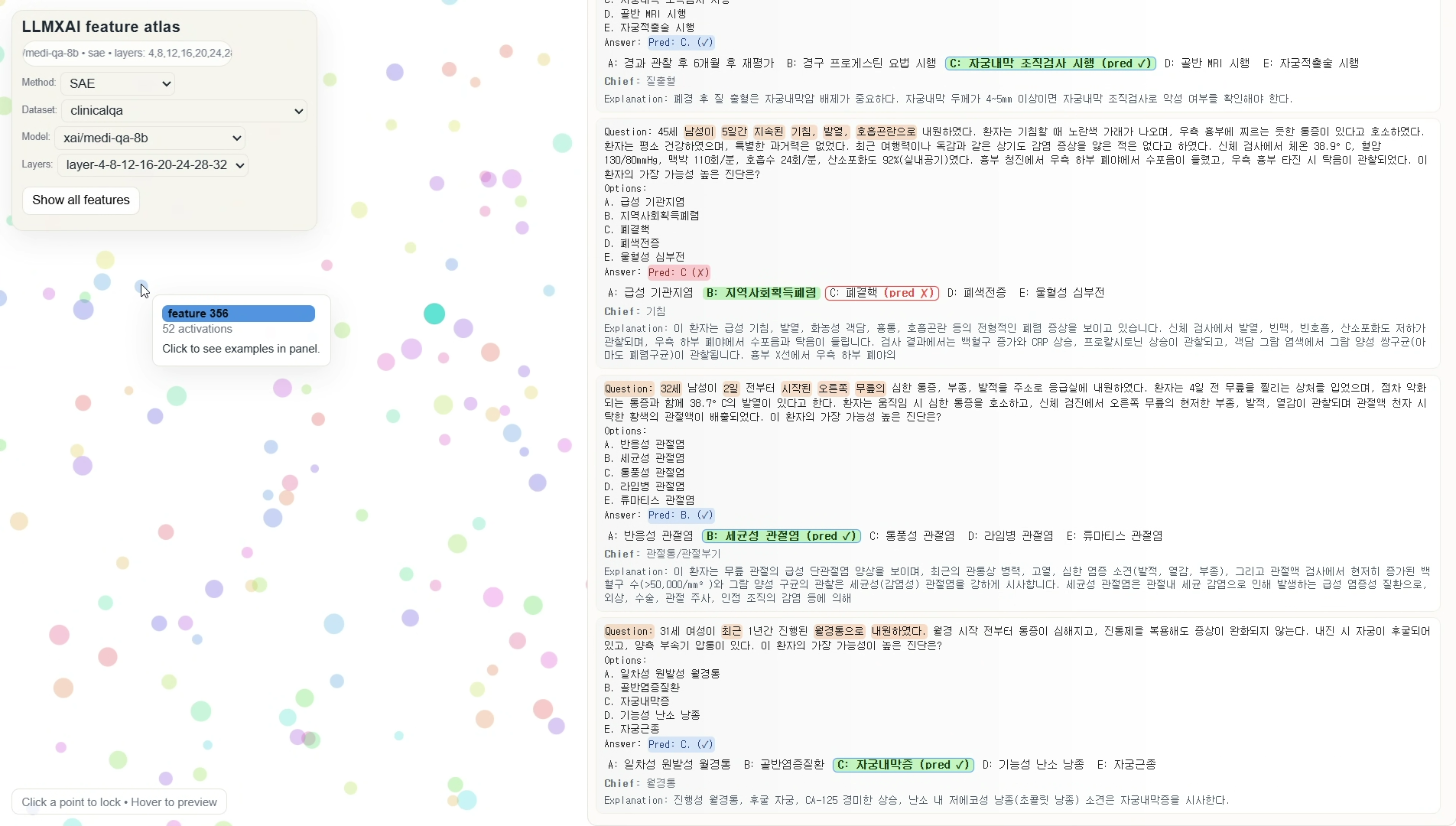
이 인터페이스는 오른쪽 패널에 추출된 특징과 관련 텍스트 코퍼스를 표시한다. 또한 문제와 선택지를 보여주고, 모델의 예측 결과와 정답을 함께 표시하며, 전문가가 제공한 해설도 함께 제공한다.
향후 연구 방향
현재 제안한 인터페이스를 구현 중이며, 다양한 데이터셋과 모델을 대상으로 실험을 진행하고 있다.
또한 도메인 지식을 활용하여 LLM 내부 활성화를 분석하고, 이를 전문가가 제공한 설명과 비교 평가할 예정이다. 추출된 특징을 증폭하거나 억제함으로써 LLM의 행동을 조정(steering)하는 것도 가능하다.
추가적으로 Sparse Feature Circuits (Marks et al., 2025) , Automated Circuit Discovery (Bhaskar et al., 2024) , 그리고 기타 Transformer Circuit 관련 연구들 (Elhage et al., 2021); (Dunefsky et al., 2024) 도 실험할 계획이다.
향후 연구에서는 임상 환경에서의 실제 추론 과정을 보다 잘 반영할 수 있는 새로운 인간-LLM 상호작용 방식을 제안하고자 한다. 이를 통해 의료 LLM의 조작성(steerability), 검증 가능성(verifiability), 설명 가능성(explainability)을 향상시키는 것을 목표로 한다.
References
- Saab, K., Tu, T., Weng, W.-H., Tanno, R., Stutz, D., Wulczyn, E., Zhang, F., Strother, T., Park, C., Vedadi, E., & others. (2024). Capabilities of Gemini Models in Medicine. ArXiv Preprint ArXiv:2404.18416.
- Singhal, K., Azizi, S., Tu, T., Mahdavi, S. S., Wei, J., Chung, H. W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., & others. (2023). Towards Expert-Level Medical Question Answering with Large Language Models. ArXiv Preprint ArXiv:2305.09617.
- Kim, H. J., Jung, K., Shin, S., Lee, W., Lee, J. H., Park, H. S., & Choi, Q. (2025). Performance evaluation of large language models on Korean medical licensing examination: a three-year comparative analysis. Scientific Reports, 15(1), 36082. doi: 10.1038/s41598-025-20066-x
- Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models. ArXiv Preprint ArXiv:2309.08600.
- Olshausen, B. A., & Field, D. J. (1997). Sparse coding with an overcomplete basis set: A strategy employed by V1? Vision Research, 37(23), 3311–3325.
- Kweon, S., Choi, B., Chu, G., Song, J., Hyeon, D., Gan, S., Kim, J., Kim, M., Park, R. W., & Choi, E. (2024). KorMedMCQA: Multi-Choice Question Answering Benchmark for Korean Healthcare Professional Licensing Examinations. ArXiv Preprint ArXiv:2403.01469.
- SNUH, H. A. I. R. I. (H. A. R. I.- S. N. U. H. (2025). Hari-q3. https://huggingface.co/snuh/hari-q3
- Marks, S., Rager, C., Michaud, E. J., Belinkov, Y., Bau, D., & Mueller, A. (2025). Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models. The Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=I4e82CIDxv
- Bhaskar, A., Wettig, A., Friedman, D., & Chen, D. (2024). Finding Transformer Circuits With Edge Pruning. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=8oSY3rA9jY
- Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., & others. (2021). A Mathematical Framework for Transformer Circuits. Transformer Circuits Thread. https://transformer-circuits.pub/2021/framework/index.html
- Dunefsky, J., Chlenski, P., & Nanda, N. (2024). Transcoders find interpretable LLM feature circuits. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=J6zHcScAo0