
A question from AI702 class. Writing in progress, and includes "tranformer" generated content. I think I'll think about this question more deeply, and add more content.
让我们来看一下这个直观的可视化 (LLM Visualization — Bbycroft.net, n.d.) 。
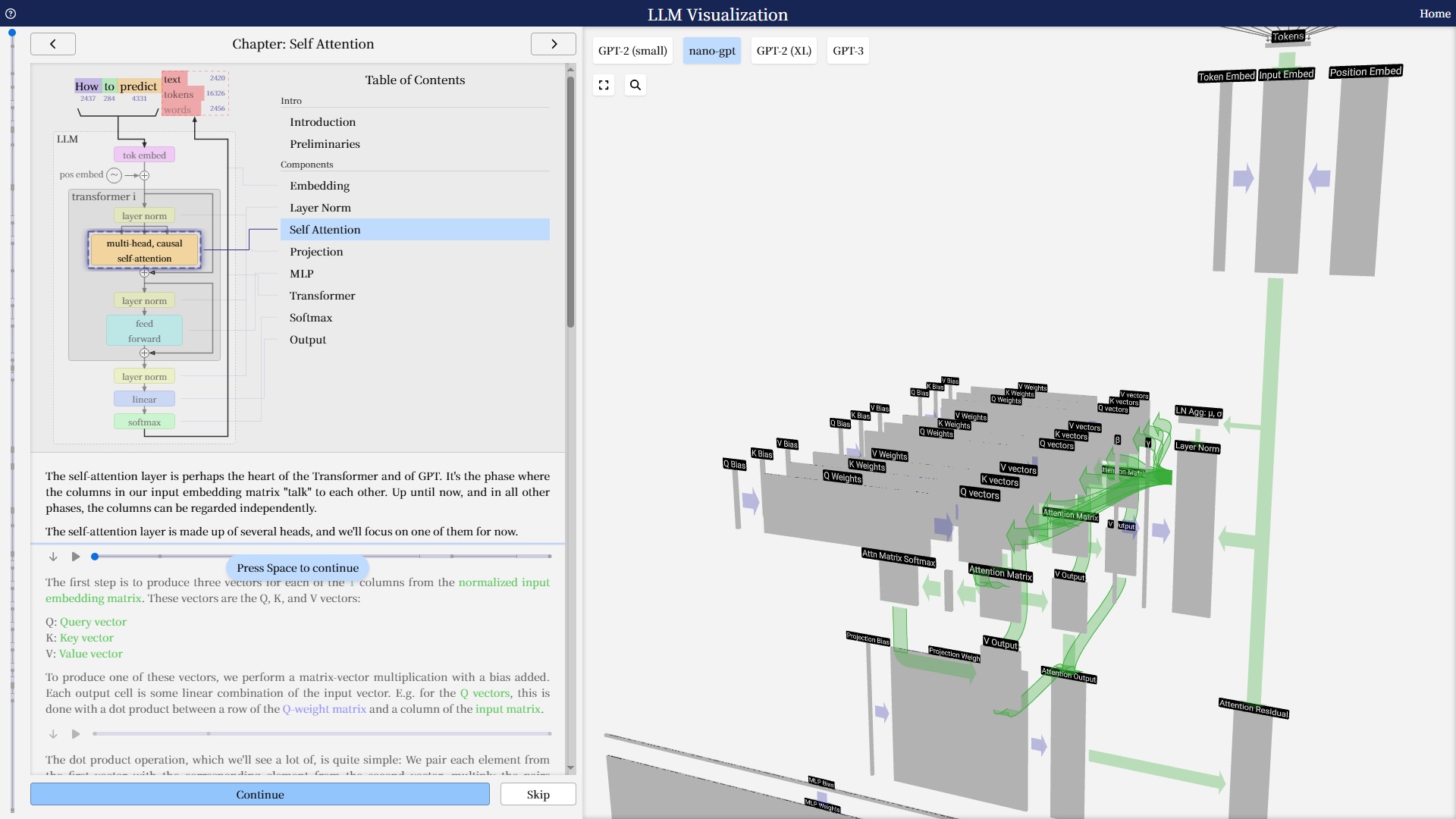 一个交互式的大语言模型(LLM)可视化。
一个交互式的大语言模型(LLM)可视化。
Transformer 中最重要的组成部分是什么?
Transformer 中最重要的组成部分是什么?
来自 KAIST 的一门课程
Self-Attention(自注意力机制)是 Transformer (Vaswani et al., 2017) 模型中最重要的组成部分。它能够衡量输入序列中不同部分之间的相关性,使模型能够理解长距离依赖关系以及全局上下文(global context)。特别是在 Multi-Head Attention(多头注意力) 的形式下,这一机制正是 Transformer 超越传统 RNN 和 CNN 的关键原因。
Self-Attention 的工作原理
- 输入表示(Input Representation):输入序列中的每个单词(或 token)都会被映射成三个向量:Query(Q)、Key(K)和 Value(V)。
- 注意力分数(Attention Scores):模型计算当前单词的 Query 与序列中所有单词的 Key 的点积(dot product),以衡量它们之间的相关性。
- 加权求和(Weighted Values):这些分数经过缩放(scaling)并通过 softmax 函数转换为注意力权重,然后用于对 Value 向量进行加权求和。
- 上下文化输出(Contextual Output):最终,每个单词都会得到一个结合了整个序列上下文信息的新向量表示,从而捕获词语之间的关系。
为什么它如此重要
- 全局上下文(Global Context):与按顺序处理信息的 RNN 不同,自注意力机制能够同时查看所有单词,从而获得全局视角。
- 长距离依赖(Long-Range Dependencies):它能够有效捕捉句子中相距较远的词语之间的关系,这对于理解复杂语言至关重要。
- 并行计算(Parallelization):注意力计算可以完全并行化,因此具有更高的计算效率和扩展性。
除了 Self-Attention,还有哪些重要的 Transformer 组件?
除了 Self-Attention 之外,Transformer 架构还依赖以下关键组件:
- 位置编码(Positional Encoding):由于 Self-Attention 同时处理所有 token,因此天然缺乏顺序信息。位置编码为每个 token 注入相对或绝对位置信息。否则,模型将无法区分“狗咬人”和“人咬狗”。
- 前馈网络(Feed-Forward Networks, FFN):每个 Self-Attention 层之后都会接一个逐位置(position-wise)的全连接网络。FFN 通过非线性变换帮助模型学习更复杂的模式和关系。
- 编码器-解码器结构(Encoder-Decoder Architecture):原始 Transformer 采用双模块结构。Encoder 负责处理输入并生成上下文表示;Decoder 则利用这些表示以及先前生成的内容来生成输出序列。
- 残差连接与层归一化(Residual Connections & Layer Normalization):
- 残差连接(Skip Connections) 将层输入直接加到输出上,从而缓解深层网络中的梯度消失问题。
- 层归一化(Layer Normalization) 对每个子层的输出进行归一化,使训练过程更加稳定。
- 词嵌入(Word Embeddings):将输入文本中的 token 转换为高维向量表示,以便模型进行处理。模型会在训练过程中不断优化这些表示。
- 交叉注意力(Cross-Attention):在 Encoder-Decoder 架构中,Decoder 通过 Cross-Attention 查看 Encoder 的输出,从而在生成内容时关注输入中的相关部分。
尽管 Self-Attention 是 Transformer 最具创新性和代表性的部分,但真正赋予 Transformer 强大能力的,是所有这些组件的协同作用。
可视化
在观看完这个视频之后,请提出一种理解或可视化基于 Transformer 的 LLM 决策边界(decision boundary)或生成边界(generation boundary)的方法。
崔教授
IPAM 2023 Towards Novel Insight Workshop: “Explainable AI to Analyze Internal Decision Mechanism of Deep Neural Networks”
我非常喜欢 EG-BAS 这篇论文 (Jeon et al., 2020) 。
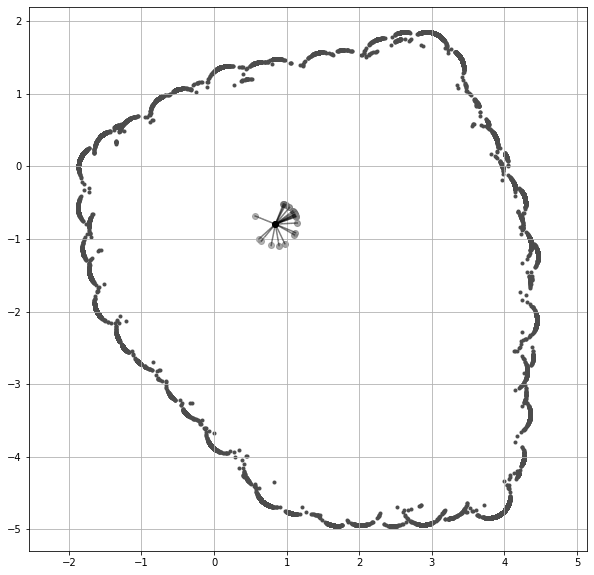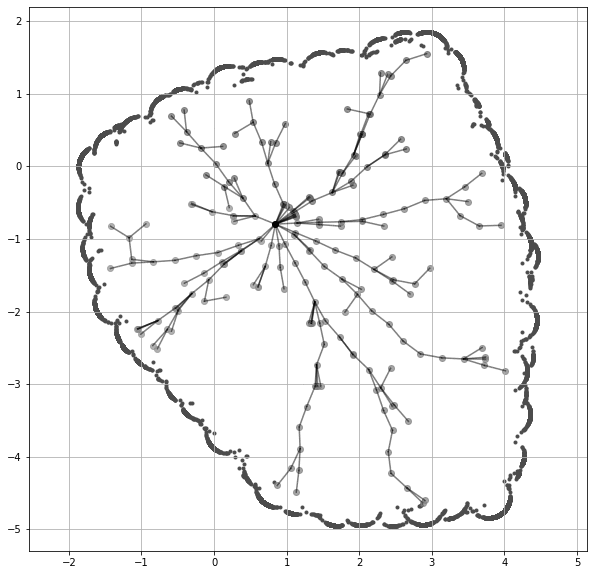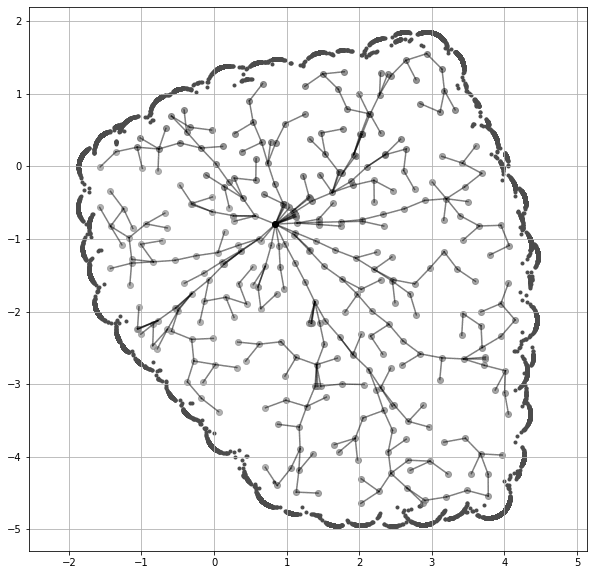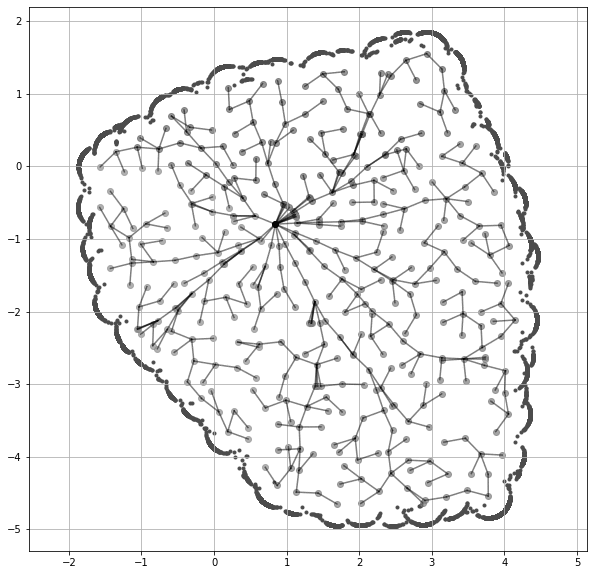 1998 年提出的 Rapidly-exploring Random Tree(RRT)。
1998 年提出的 Rapidly-exploring Random Tree(RRT)。
对于机器人领域的研究者来说,RRT (LaValle, 1998) 再熟悉不过了。我认为可以借鉴类似的思想,为 LLM 设计一种新的可视化方式。
我同样非常喜欢 Anthropic 的这张可视化图 (Mapping the Mind of a Large Language Model — Anthropic.com, n.d.) 。
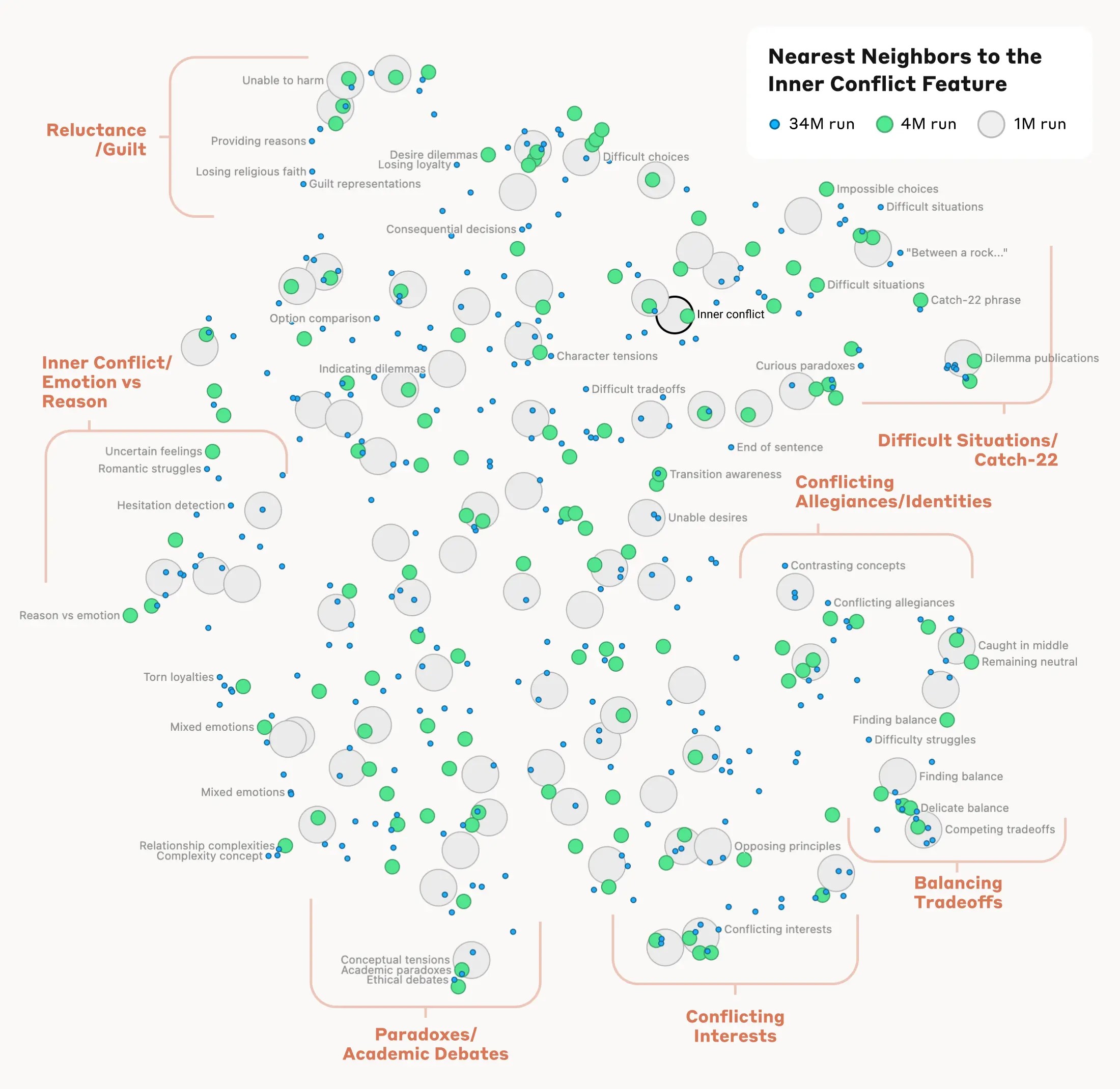 Anthropic 绘制的“心智地图(Mapping the Mind)”。
Anthropic 绘制的“心智地图(Mapping the Mind)”。
未完待续
深入思考 Transformer 的每一个组成部分,往往能够带来新的洞见和研究灵感。
未完待续……
References
- LLM Visualization — bbycroft.net.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. CoRR, abs/1706.03762. http://arxiv.org/abs/1706.03762
- Jeon, G., Jeong, H., & Choi, J. (2020). An efficient explorative sampling considering the generative boundaries of deep generative neural networks. Proceedings of the AAAI Conference on Artificial Intelligence, 34(04), 4288–4295.
- LaValle, S. M. (1998). Rapidly-exploring random trees : a new tool for path planning. The Annual Research Report. https://api.semanticscholar.org/CorpusID:14744621
- Mapping the Mind of a Large Language Model — anthropic.com.