
A question from AI702 class. Writing in progress, and includes "tranformer" generated content. I think I'll think about this question more deeply, and add more content.
직관적인 시각화) (LLM Visualization — Bbycroft.net, n.d.) 를 살펴보자.
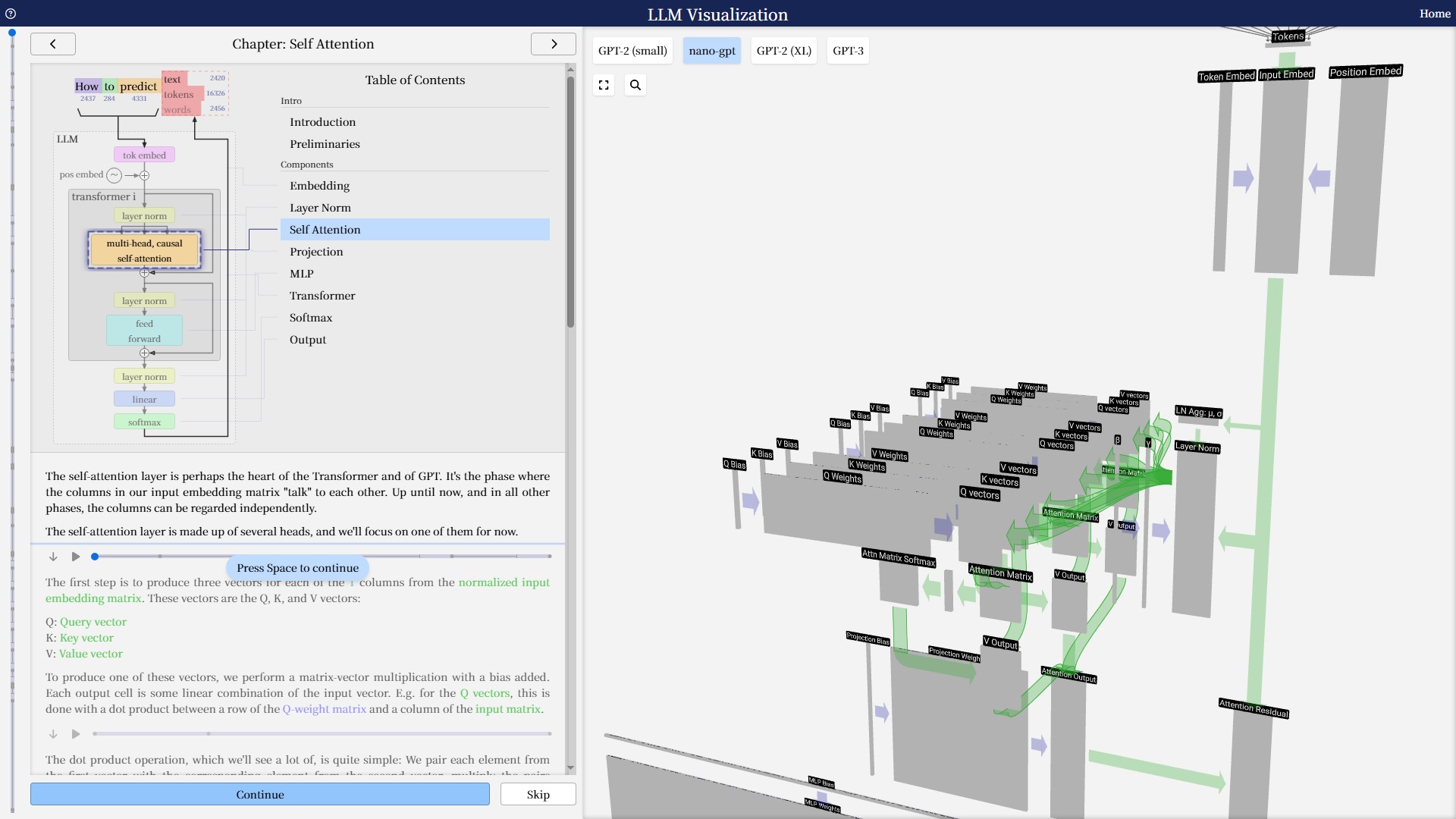 LLM을 인터랙티브하게 시각화한 예시.
LLM을 인터랙티브하게 시각화한 예시.
트랜스포머에서 가장 중요한 구성 요소는 무엇일까?
트랜스포머에서 가장 중요한 구성 요소는 무엇인가?
KAIST 수업 중에서
Self-Attention 메커니즘은 Transformer (Vaswani et al., 2017) AI 모델에서 가장 중요한 구성 요소이다. 이는 입력 시퀀스 내 서로 다른 부분들의 중요도를 상대적으로 평가할 수 있게 해주며, 모델이 장거리 의존성(long-range dependency)과 전역적인 문맥(global context)을 이해하도록 만든다. 특히 Multi-Head Attention 형태로 구현될 때, Transformer가 기존의 RNN이나 CNN보다 뛰어난 성능을 보이는 핵심 이유가 된다.
Self-Attention은 어떻게 동작하는가
- 입력 표현(Input Representation): 입력 시퀀스의 각 단어(또는 토큰)는 Query(Q), Key(K), Value(V) 세 개의 벡터로 변환된다.
- 어텐션 점수 계산(Attention Scores): 특정 단어의 Query 벡터와 시퀀스 내 모든 단어의 Key 벡터 간 내적(dot product)을 계산한다. 이 점수는 현재 주목하는 단어와 다른 단어들이 얼마나 관련 있는지를 나타낸다.
- 가중합 계산(Weighted Values): 계산된 점수를 스케일링한 뒤 softmax 함수를 적용하여 attention weight를 얻고, 이를 이용해 Value 벡터들의 가중합을 계산한다.
- 문맥적 출력(Contextual Output): 최종적으로 각 단어는 전체 시퀀스의 문맥을 반영한 벡터 표현을 얻게 되며, 이를 통해 단어들 사이의 관계가 표현된다.
왜 중요한가
- 전역 문맥(Global Context): 순차적으로 처리하는 RNN과 달리, Self-Attention은 모든 단어를 동시에 바라볼 수 있어 전역 문맥을 제공한다.
- 장거리 의존성(Long-Range Dependencies): 문장 내 멀리 떨어진 단어들 간의 관계를 효과적으로 포착할 수 있으며, 이는 복잡한 언어 이해에 필수적이다.
- 병렬화(Parallelization): Attention 연산은 병렬 계산이 가능하기 때문에 계산 효율성과 확장성이 높다.
Self-Attention 외에 중요한 Transformer 구성 요소들은 무엇인가?
Self-Attention 외에도 Transformer 아키텍처를 구성하는 중요한 요소들은 다음과 같다.
- Positional Encoding (위치 인코딩): Self-Attention은 모든 단어를 동시에 처리하기 때문에 순서 정보를 잃게 된다. Positional Encoding은 각 토큰의 상대적 혹은 절대적 위치 정보를 추가한다. 이것이 없다면 모델은 “개가 사람을 문다”와 “사람이 개를 문다”를 구분할 수 없다.
- Feed-Forward Network (FFN): 각 Self-Attention 층 뒤에는 위치별 완전연결 신경망이 위치한다. FFN은 비선형 변환을 적용하여 더 복잡한 패턴과 관계를 학습하게 한다.
- Encoder-Decoder 구조: 원래 Transformer는 두 부분으로 구성된다. Encoder는 입력을 처리하여 문맥 표현을 생성하고, Decoder는 이를 이용해 최종 출력 시퀀스를 생성한다.
- Residual Connection과 Layer Normalization: 학습을 안정화하고 가속화한다.
- Residual Connection (Skip Connection) 은 층의 입력을 출력에 더해 기울기 소실 문제를 완화한다.
- Layer Normalization 은 각 서브레이어의 출력을 정규화하여 학습이 불안정해지는 것을 방지한다.
- Word Embedding: 단어 또는 서브워드를 고차원 벡터 공간으로 변환한다. 학습 과정에서 이 임베딩 역시 함께 최적화된다.
- Cross-Attention (Decoder 내부): Encoder-Decoder 구조에서 Decoder는 Cross-Attention을 통해 입력 문장의 중요한 부분에 집중하며 출력을 생성한다.
Self-Attention이 가장 혁신적이고 상징적인 구성 요소인 것은 사실이지만, Transformer의 강력함은 결국 이러한 요소들이 함께 작동하는 데서 나온다.
시각화
영상을 시청한 후, Transformer 기반 LLM의 의사결정/생성 경계를 이해하거나 시각화할 수 있는 방법을 제안하시오.
최 교수님
IPAM 2023 Towards Novel Insight Workshop: “Explainable AI to Analyze Internal Decision Mechanism of Deep Neural Networks”
나는 EG-BAS 논문 (Jeon et al., 2020) 을 매우 좋아한다.
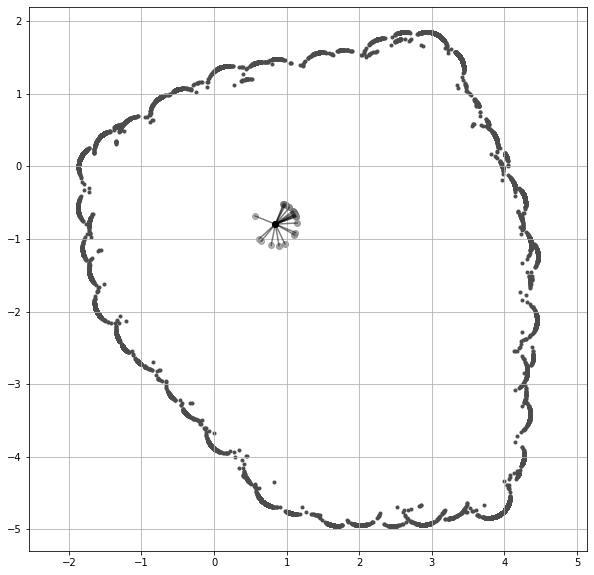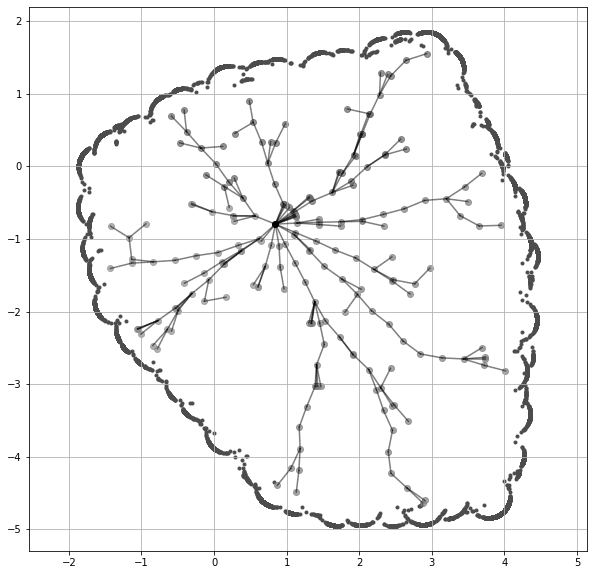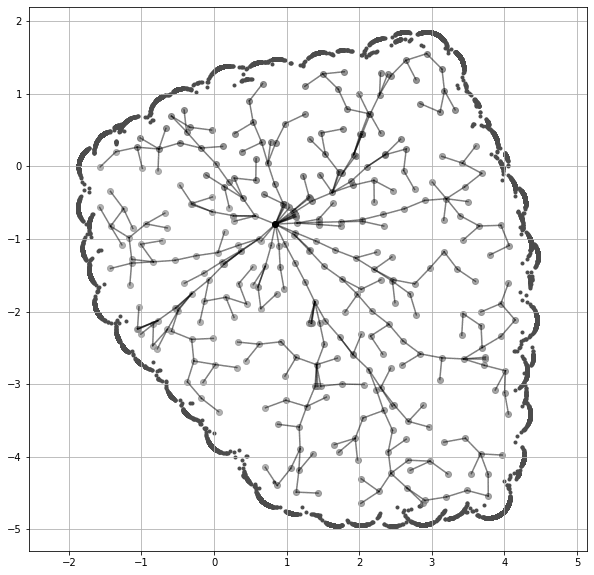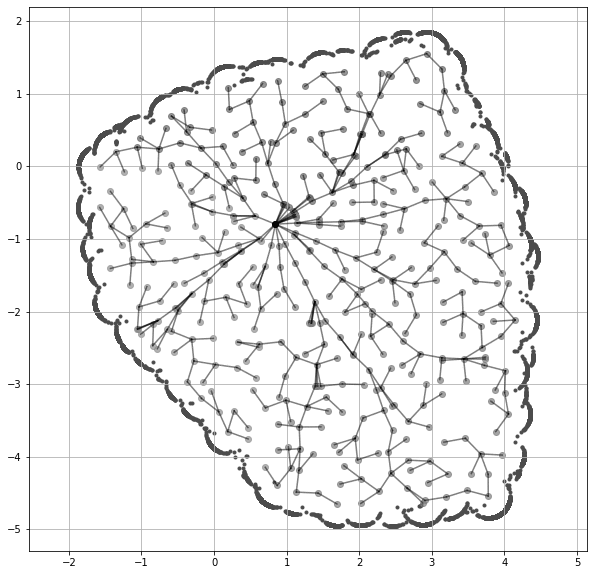 1998년에 제안된 Rapidly-exploring Random Tree (RRT).
1998년에 제안된 Rapidly-exploring Random Tree (RRT).
물론 RRT (LaValle, 1998) 는 로보틱스 연구자라면 누구나 익숙하다. 나는 이와 유사한 스타일의 시각화를 LLM에도 적용할 수 있을 것 같다.
또한 Anthropic의 다음 시각화도 매우 인상적이다 (Mapping the Mind of a Large Language Model — Anthropic.com, n.d.) .
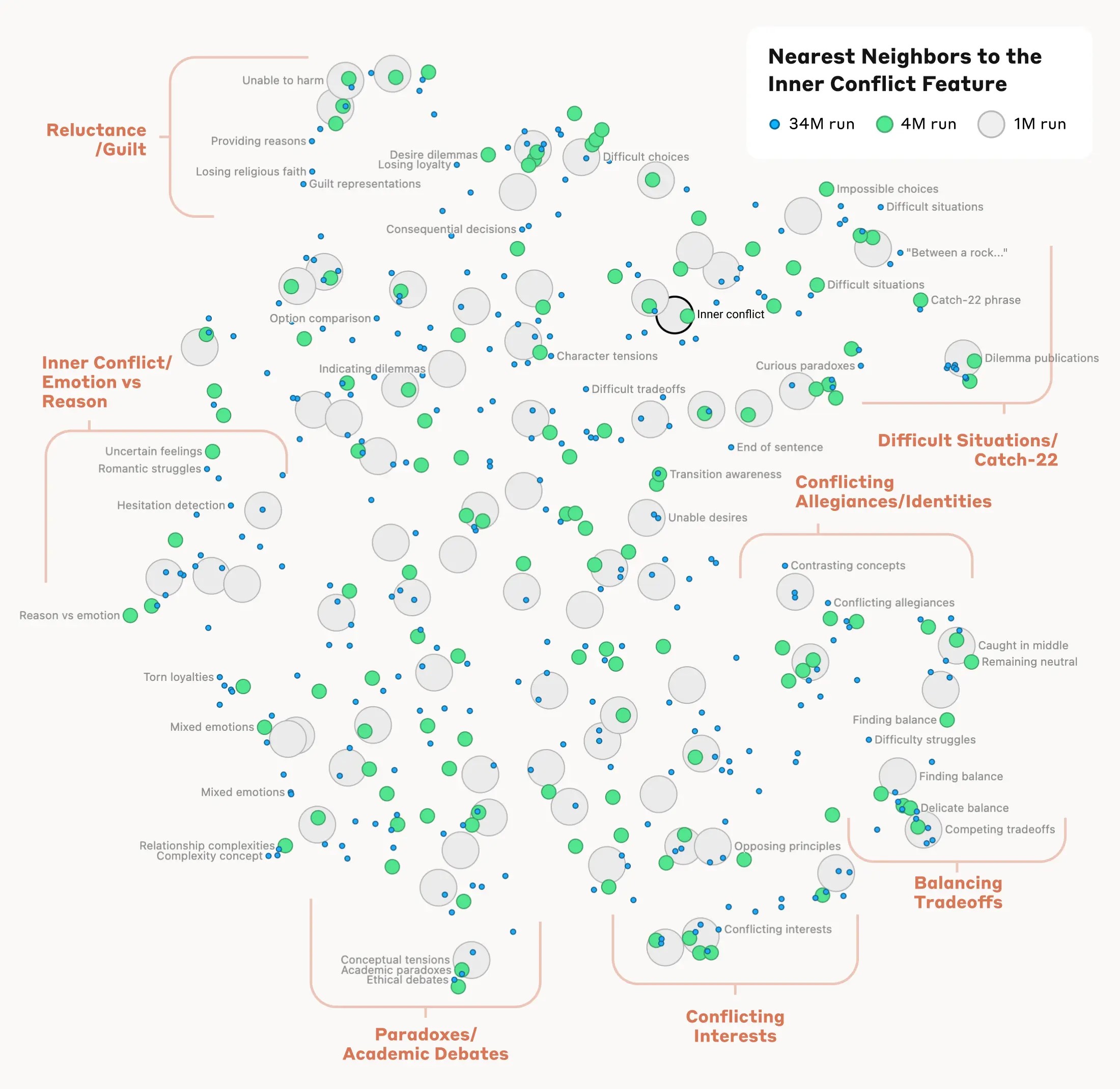 Anthropic이 그린 “마음의 지도”.
Anthropic이 그린 “마음의 지도”.
계속
각 구성 요소를 깊이 이해하려고 시도하는 과정 자체가 새로운 통찰과 연구 아이디어를 제공할 것이다.
계속…
References
- LLM Visualization — bbycroft.net.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. CoRR, abs/1706.03762. http://arxiv.org/abs/1706.03762
- Jeon, G., Jeong, H., & Choi, J. (2020). An efficient explorative sampling considering the generative boundaries of deep generative neural networks. Proceedings of the AAAI Conference on Artificial Intelligence, 34(04), 4288–4295.
- LaValle, S. M. (1998). Rapidly-exploring random trees : a new tool for path planning. The Annual Research Report. https://api.semanticscholar.org/CorpusID:14744621
- Mapping the Mind of a Large Language Model — anthropic.com.